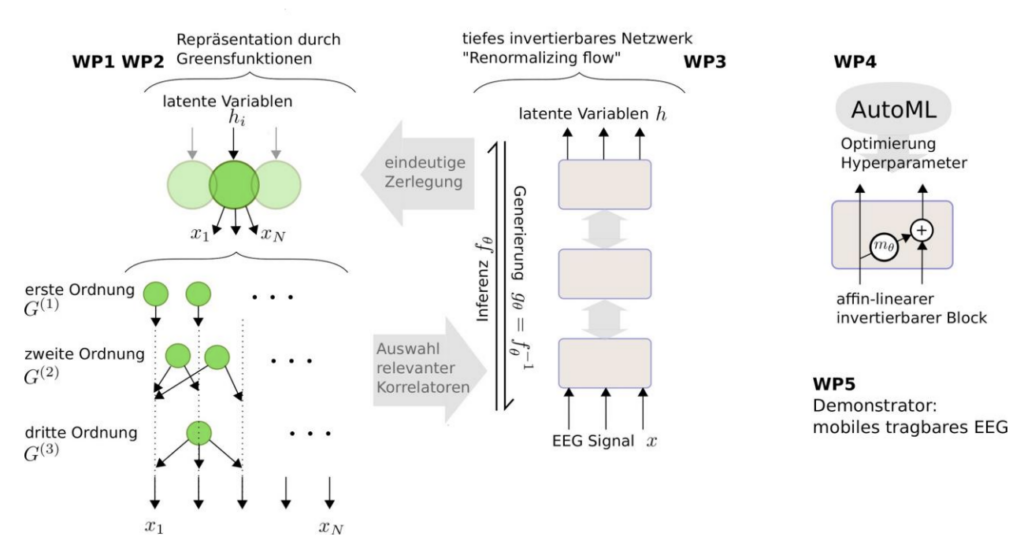
The RenormalizedFlows project aims at fostering transparency and interpretability in medical AI systems. The present project focuses on the analysis of brain signals, i.e. electroencephalogram (EEG) data, as an example of medical time series analysis; a topic that has broad applications, both in the context of neurotechnology and in diagnostics. Concretely we aim to apply the recent advances in Neural Architecture Search (NAS), Hyperparameter Optimization (HPO) to optimize the architecture and the hyperparameters respectively of the invertible renormalized flow architectures. Further we use Meta Learning to study how the knowledge previously generated on other data sets can be transferred to new data sets.
We aim to address the following research questions:
RQ1: How important are the hyperparameters of the training-pipeline for invertible normalizing flows networks?
Hyperparameter settings have been adopted from standard architectures, and it is possible that these are suboptimal for the changed architectures. This explains the difference in performance between these interpretable architectures and standard architectures. Hence applying Hyperparameter Optimization (HPO) to the designed invertible networks becomes crucial.
RQ2: Can we optimize the architecture of the invertible normalizing flows networks?
Similar to the hyperparameters of the training pipeline, the invertible architecture itself
can be optimized (under the constraint that it remains invertible). While Neural Architecture Search (NAS) methods based on network morphisms are directly applicable here, the existing gradient-based NAS methods need to be adapted for invertible networks.
RQ3: To what extent a model that has been pre-trained on other data sets can be transferred to new, comparatively small data sets through fine tuning?
This research question necessitates the use of Meta-Learning across datasets to (a) set the associated hyperparameters (such as the learning rate for adaptation to the new dataset), and (b) make decisions about the architecture which is optimal for this transfer. Meta-learning should enable us to work on small datasets without overfitting.